
Reinforcement learning with human feedback (RLHF) is a technique for training large language models (LLMs). Instead of training LLMs merely to predict the next word, they are trained with a human conscious feedback loop to better understand instructions and generate helpful responses which minimizes harmful, untruthful, and/or biased outputs.
RLHF Vs. Non-RLHF
LLMs are trained with a vast amounts of text data and capable to predict the next word in a given sequence. However this output may not always be aligned with the human desired output. For example (Referred from Introduction to Reinforcement Learning with Human Feedback (surgehq.ai) if you ask a non-RLHF (GPT-3) model to “Generate a story about Harry Potter using AI to fight Voldemort” the response would be something like:

The outputs will vary depending upon the prompt from the user. However, like discussed earlier, the output is most of the times not aligned with the human expectations. This is where the “Human Training Loop” to create the Reward Model for RLHF comes into use. I asked the same question to RLHF Model (ChatGPT) which uses the Supervised Machine Learning Technique along with RLHF.

Reading through the responses, we can easily distinguish between a RLHF and non-RLHF models. The human feedback trained reward model helps the RLHF AI to give more desirable output.
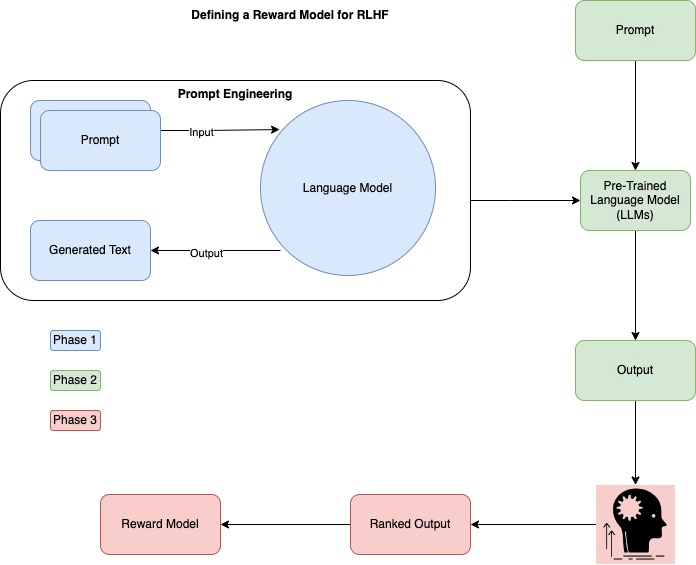
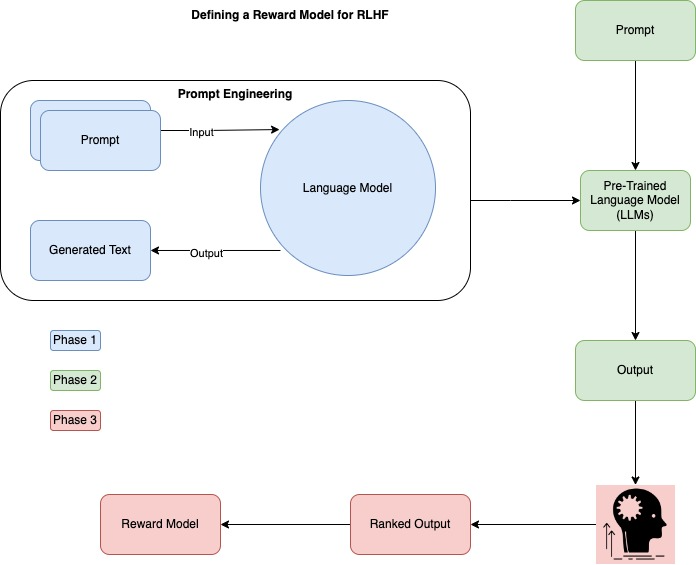
The following diagram represents the high level flow on how to the LLMs are trained using Prompt Engineering and it becomes the main LLM to train the RLHF model with human feedback. Further more it uses the new Reward model to predict the next best text.
Constraints to scale:
RLHF is definitely the next best think in AI. It has lots of potential. It can predict more text, with more human desirability than the non-RLHF models. In fact, OpenAI found that RLHF models are vastly more efficient: their 1.3B-parameter RLHF model outperformed their 175B-parameter non-RLHF model, despite having more than 100x fewer parameters!
However, RLHF relies upon humans being able to evaluate the outputs of models. How easy or difficult this will become in the future to train large peta bytes of data is something interesting to look for.
Usage:
RLHF has shown success with OpenAI’s ChatGPT and InstructGPT models, Few other AI’s which use RLHF training models DeepMind’s Sparrow, Anthropic’s Claude, etc.
Further Reading:
Introduction to Reinforcement Learning with Human Feedback (surgehq.ai)
How ChatGPT actually works (assemblyai.com)
What is reinforcement learning from human feedback (RLHF)? — TechTalks (bdtechtalks.com)
